Skip to main content
Skip to main content
 Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
Rapita Systems Collaborates with Wind River to Break the Multicore Certification Barrier
 Rapita Systems Launches Next Generation of MACH178 for Multicore
Rapita Systems Launches Next Generation of MACH178 for Multicore
 RVS 3.24 accelerates multicore software verification
RVS 3.24 accelerates multicore software verification
 Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
Rapita Systems and Avionyx Announce Strategic Partnership to Offer Best-in-class Avionics Solutions
 The Evolution of DO 178 and ED-12 Standards
The Evolution of DO 178 and ED-12 Standards
 Retro gaming with the Sim68020
Retro gaming with the Sim68020
 RVS gets a new timing analysis engine
RVS gets a new timing analysis engine
 How to measure stack usage through stack painting with RapiTest
How to measure stack usage through stack painting with RapiTest
 How to achieve multicore DO-178C certification with Rapita Systems
How to achieve multicore DO-178C certification with Rapita Systems
 How to achieve DO-178C certification with Rapita Systems
How to achieve DO-178C certification with Rapita Systems
 Certifying Unmanned Aircraft Systems
Certifying Unmanned Aircraft Systems
 DO-278A Guidance: Introduction to RTCA DO-278 approval
DO-278A Guidance: Introduction to RTCA DO-278 approval
 DO-178C Multicore Virtual Training
DO-178C Multicore Virtual Training
 HISC 2026
HISC 2026










Recently I chanced upon a discussion among some undergraduates studying Computer Science. They were debating whether programmers should routinely employ efficient bit-manipulation in their source code rather than trusting that the compiler will do a good job on a more straightforward representation of the algorithm. My initial thought was "why is this even a question these days?"
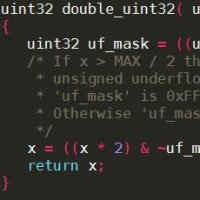
The canonical source is on Standford's website and is a treasure-trove of interesting snippets. Let's take a convenient and simple example, testing whether a word has a single bit set:
f = v && !( v & (v-1) )
With a little bit of thought, it's possible to see what this is doing - when you subtract 1 from a number, its bit-representation has the same top bit set except in the cases where the borrow goes all the way to the top bit - in which case it was a power of two. The wrinkle is that zero passes this plain test, so it's necessary to discount that possibility by explicitly catching the case where the input is zero.
The equivalent explicit form would be something like the following:
int bitset_loop32( int v )
{
int b = 0;
int k = 0;
unsigned int m = 1;
for( b = 0; b < 32; b++ )
{
if( v & m )
{
k++;
}
m <<= 1;
}
return k == 1;
}
Which one is "best"? The one-liner is a low-level optimization where the behaviour is only apparent after some thought, so there are several factors to think about:
- The bit-hack version is concise, so you can see everything that the code is doing right there in one line, although it takes some effort to figure out what it's doing.
- The one-liner is also expressed in very low-level terms, so it will likely trace better to the object code.
- However, since it's already in low-level terms, there's not much scope for a compiler to optimise it.
- However, if you're really looking for source to object code traceability, that's possibly a good thing, as it means your code will largely be where you said you wanted it.
- The bit-twiddling doesn't use any extra storage (from the perspective of the source code) compared to the bitset_loop approach.
- Since it doesn't include a loop, the one-liner version is more likely to have predictable execution time.
- The looping version is of a form that's typically easier to relate to higher-level requirements, especially when it comes to traceability and independent review.
- Although it's not so relevant for this example, maintaining and debugging an explicit-but-inefficient implementation is generally easier than doing so on the equivalent optimized version.
My advice, coming from a background where reviews and justification are important, would be:
- Make sure you have the explicit version and the optimized version available side by side in some way. You could keep the explicit version in a comment or perhaps include a way of configuring the code to be able to test one or the other in a test-suite (or even to test them together.)
- Don't fall into the trap of convenient premature optimizations without first seeing if this is an optimization worth doing. Test early and often, and you'll focus your effort on problems that are important to solve.
- If you care about efficiency enough to use it as justification for optimizations, then you should be measuring your execution times for whatever target environment(s) you're running in. You will need data to show that the one-bit-set algorithm is a barrier to overall system efficiency, and you will need data to show that changing the implementation leads to improved overall system efficiency, and crucially you'll need to show that the change to the implementation is the cause of the improvement (rather than, for example, the change to the implementation changing something innocuous like memory alignments or register allocations that happen to have a knock-on improvement effect).
In the end, Sean Anderson's advice sums it up pretty well: "Benchmarking is the best way to determine whether one method is really faster than another, so consider the techniques below as possibilities to test on your target architecture."
DO-178C webinars
White papers

Mitigation of interference in multicore processors for A(M)C 20-193

Developing DO-178C and ED-12C-certifiable multicore software

Efficient Verification Through the DO-178C Life Cycle

A Commercial Solution for Safety-Critical Multicore Timing Analysis